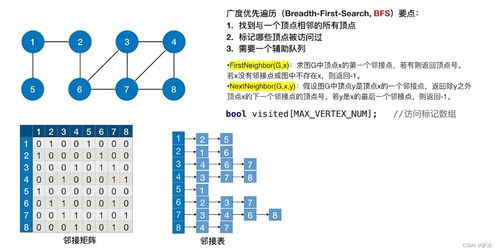
在快速迭代的技术浪潮中,大数据处理框架Apache Spark以其卓越的内存计算能力、丰富的API生态和灵活的部署方式,已成为企业级数据处理与分析的核心引擎之一。高彦杰所著的《Spark大数据处理:技术、应用与性能优化》一书,正是深入探索这一技术领域的经典指南。即使面对最新技术版本的不断涌现,这本书的系统性讲解、原理剖析与实践指引,依然为开发者与数据工程师提供了坚实的基础与深刻的洞见。
一、经典的价值:技术内核的持久性
尽管Spark的版本持续更新,但其核心设计思想与架构——如弹性分布式数据集(RDD)、统一批流处理的DataFrame/Dataset API、基于DAG的任务调度与内存管理机制——在书中得到了详尽而清晰的阐述。这些基础原理并未随版本迭代而过时,反而构成了理解任何新特性的前提。对于初学者而言,通过本书可以避免陷入追逐最新版本的焦虑,转而扎实掌握Spark的“不变”的内核,从而更快适应新版本的变化。
二、系统全面:从技术细节到生态系统
本书的副标题“技术、应用与性能优化”精准概括了其内容维度。它不仅深入讲解了Spark的各项功能(如Spark SQL、Spark Streaming、MLlib、GraphX),还涵盖了性能调优的实用技巧(包括内存优化、分区策略、序列化配置等),并结合BDAS(Berkeley Data Analytics Stack)生态系统,展现了Spark与其他大数据工具(如Hadoop、Hive、Kafka)的集成方案。这种从微观到宏观的视角,帮助读者构建起完整的大数据处理知识体系,即便在旧书市场中寻得,其知识框架依然具有高度的参考价值。
三、旧书有路:性价比与可持续学习
在“上有路”这样的旧书平台或二手渠道购买此书,是一种兼具经济性与环保意义的选择。技术书籍的“新旧”并非仅由版本决定,更重要的是其内容是否启发性与实用性并存。对于预算有限的学生、自学者或希望夯实基础的技术人员,旧书提供了低门槛的学习路径。读者可以结合本书的经典理论,再通过Spark官方文档、社区博客及最新实践案例补充新版本特性(如结构化流处理的增强、Koalas集成等),形成“旧书原理+新资料实践”的高效学习模式。
四、数据处理实践:从理论到应用
本书强调“应用与性能优化”,这正是大数据处理落地的关键。通过书中丰富的代码示例与场景分析(如日志处理、机器学习流水线、图计算应用),读者能直观理解如何将Spark技术应用于实际业务。即使书中部分API随版本更新有所调整,其解决问题的思路与优化方法论——如避免数据倾斜、合理利用缓存、动态资源分配——依然具有普适性。在旧书的基础上,读者可借助开源社区资源将案例迁移至新环境,从而锻炼出更强大的技术迁移与问题解决能力。
五、技术传承与创新同行
高彦杰的《Spark大数据处理》如同一幅详实的技术地图,虽出版于旧版,却清晰标明了通往大数据处理核心的路径。在技术快速演进的时代,“旧书”未必代表过时,反而可能沉淀了经得起时间考验的精华。对于有志于深入数据处理领域的探索者而言,不妨以本书为基石,以旧启新,在掌握本质原理的积极拥抱生态发展,让Spark的技术之光持续照亮数据智能的未来之路。