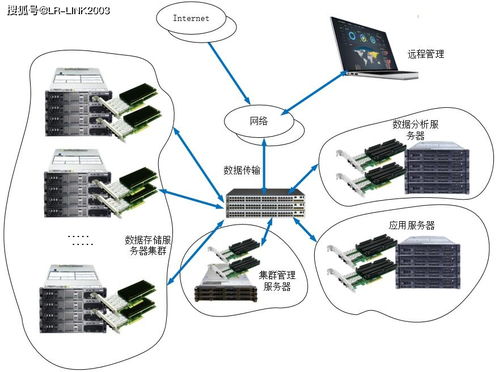
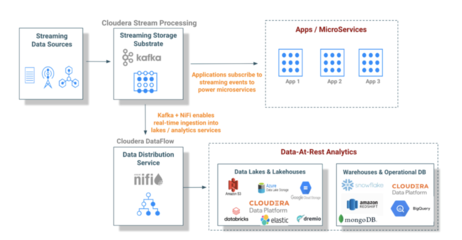
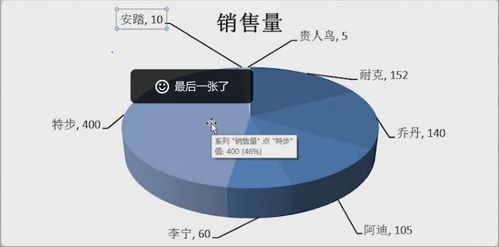
《试验设计与数据处理》是科研与工程实践中的经典教材,其第4版在内容上进行了系统更新与深化,尤其突出了数据处理在现代科学研究与工业应用中的核心地位。本书不仅延续了前三版严谨的理论体系和丰富的实例特色,还紧密结合当前大数据、人工智能等前沿技术背景,为读者提供了更为全面和实用的数据处理方法论。
数据处理:科学试验的灵魂
试验设计与数据处理是科学研究的两大支柱。试验设计关注如何高效、经济地安排试验,以获取可靠数据;而数据处理则侧重于如何从这些数据中提取有价值的信息,得出科学结论。在第4版中,作者李云雁教授强调,数据处理并非简单的数学运算,而是贯穿于试验始终的思维过程——从数据收集、整理、分析到结果解释,每一步都直接影响试验的成败。
核心内容概览
第4版的数据处理部分主要包括以下关键模块:
- 数据预处理:涉及数据清洗、异常值检测与处理、缺失值填补等方法,确保数据质量。本书介绍了统计检验和可视化技术(如箱线图、散点图)在数据筛查中的应用。
- 统计基础与分布理论:深入讲解正态分布、t分布、F分布等常见概率分布,为参数估计和假设检验奠定基础。新版增加了对非参数统计的简要介绍,以适应更广泛的数据类型。
- 方差分析与回归分析:作为试验设计的核心分析工具,本书系统阐述了单因素与多因素方差分析、线性与非线性回归模型。特别强化了模型诊断(如残差分析、多重共线性检验)和变量选择方法,帮助读者避免误用模型。
- 多元统计分析:针对多变量数据,介绍了主成分分析、聚类分析和判别分析等降维与分类技术,反映了现代数据处理对高维数据的处理需求。
- 统计软件应用:结合SPSS、R或Python等工具,提供实际案例分析,使读者能将理论快速应用于实践。第4版特别增加了基于Python的数据处理示例,契合当前编程分析的趋势。
创新与实用性
与早期版本相比,第4版的突出特点在于:
- 与时俱进的技术整合:引入了机器学习中的交叉验证、自助法等概念,拓展了传统统计的边界。
- 案例驱动学习:每章配备来自工程、生物、化学等领域的真实案例,强调数据处理的场景化应用。例如,通过化工反应优化试验的数据,演示如何利用回归分析建立产率与温度、压力的关系模型。
- 错误与陷阱警示:专门章节讨论数据处理中的常见误区,如p值滥用、相关性误解等,培养读者的批判性思维。
应用价值
本书不仅适用于高校理工科学生和研究人员,也对工业领域的工程师具有重要参考价值。在质量控制、工艺优化、新产品研发等场景中,科学的数据处理能显著提升决策效率与准确性。通过学习,读者将掌握从“数据”到“知识”的完整链条,具备独立完成试验设计与分析的能力。
《试验设计与数据处理》(第4版)以清晰的结构、丰富的实例和前沿的视角,构建了一座连接理论方法与实际应用的桥梁。数据处理不再是枯燥的数字游戏,而是探索未知、驱动创新的有力工具。无论是学术研究还是工程实践,本书都能为读者提供坚实的技术支撑与思维启发。