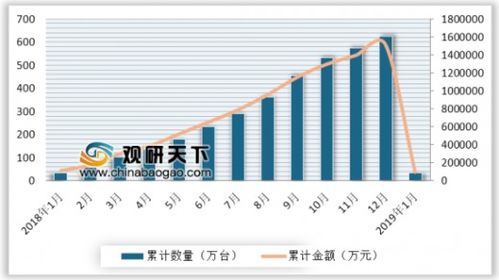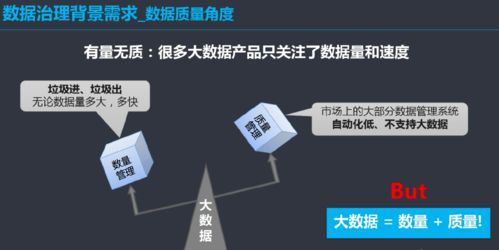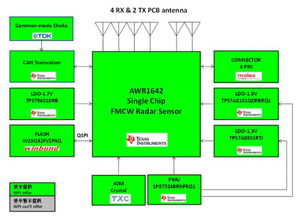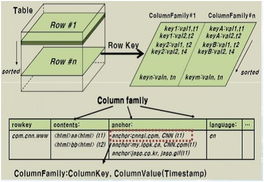
在信息爆炸的时代,海量数据处理已成为各行各业面临的共同挑战。传统的数据处理工具与方法在处理TB、PB乃至EB级别的数据时,往往显得力不从心,存在性能瓶颈、扩展性差和成本高昂等问题。为了解决这一难题,以Hadoop为代表的分布式计算框架及其核心编程模型MapReduce应运而生,为海量数据处理开辟了全新的路径。
Hadoop框架是一个开源、高可靠、高扩展的分布式系统基础架构,其核心设计思想源自Google的GFS和MapReduce论文。它主要由Hadoop Distributed File System(HDFS)和MapReduce计算模型两大部分构成。HDFS负责海量数据的分布式存储,它将大文件分割成多个数据块(Block),并将这些数据块冗余存储在集群中的多个节点上,从而实现了数据的高容错性和高吞吐量访问。这种存储方式为后续的并行计算奠定了坚实的基础。
而MapReduce则是Hadoop处理海量数据的核心计算范式。它将复杂的计算任务抽象为两个主要阶段:Map(映射)和Reduce(归约)。在Map阶段,输入数据被分割成独立的片段,由集群中的多个节点并行处理,每个节点对其分配的数据片段执行用户定义的Map函数,生成一系列的中间键值对(key-value pairs)。这些中间结果经过一个Shuffle(混洗)过程,将相同key的数据汇聚到同一个节点。随后进入Reduce阶段,该节点对汇聚过来的、属于同一key的所有value执行用户定义的Reduce函数,最终产生输出结果。
这种“分而治之”的模式具有显著优势。它实现了极高的并行性,通过增加集群中的节点数量,可以线性地提升数据处理能力,轻松应对数据规模的持续增长。它将计算任务移动到数据所在的节点(移动计算而非移动数据),极大地减少了数据在网络中的传输开销。其编程模型相对简单,开发者只需关注Map和Reduce两个核心逻辑,而无需操心复杂的分布式系统问题,如任务调度、节点通信和容错处理等,这些都由Hadoop框架自动管理。当某个计算节点失败时,框架能够自动检测并将该节点上的任务重新调度到其他健康节点执行,确保作业的最终完成。
Hadoop与MapReduce的应用场景极为广泛。从互联网公司的用户日志分析、搜索引擎的网页索引构建,到金融领域的风险建模与欺诈检测,再到生物信息学的基因序列分析,其身影无处不在。它使得从海量、多源、异构的数据中挖掘有价值的信息变得可行且高效。
技术也在不断演进。经典的MapReduce模型由于其基于磁盘的中间结果存储和较为固定的两阶段模型,在处理需要多轮迭代或实时交互的场景时存在延迟较高的问题。因此,在Hadoop生态之上,又诞生了如Spark这样基于内存计算的下一代计算框架,它通过弹性分布式数据集(RDD)等抽象,在兼容MapReduce优点的显著提升了迭代计算和交互式查询的性能。
Hadoop框架及其MapReduce模式是海量数据处理发展史上的里程碑。它们不仅提供了切实可行的技术解决方案,更重要的是,其背后所蕴含的分布式、并行化、面向大规模廉价硬件的设计哲学,深刻影响了整个大数据技术栈的发展。理解Hadoop与MapReduce,是理解现代大数据处理技术基石的关键一步。随着数据规模的持续膨胀和应用需求的不断深化,其核心思想仍将在新的技术形态中延续与升华,继续驱动着海量数据处理能力的边界不断拓展。